Hash Tables
Before we get into how it works, let me just say: hashing is everywhere. Every time you log into a website, run a spell checker, search a string, or import a Python dict, hashing is doing the work quietly in the background.
It's probably the most used data structure in all of computer science. And once you understand it, you'll start seeing it everywhere too.
So What Even Is a Dictionary?
A dictionary (also called a hash table) is a data structure that stores a set of items, where each item has a key. Three operations, that's it:
- Insert an item
- Delete an item
- Search for a key → either you find it, or you don't
The interesting one is search. And it's exact search , you either know the key you're looking for, or you're out of luck.
In Python, you already know this thing:
d = {}
d["name"] = "ali" # insert
del d["name"] # delete
d["name"] # search → "ali" or KeyError
One rule: keys are unique. Insert with an existing key? It overwrites. That's Python's behavior, and it's what we'll assume throughout.
This is different from a binary search tree. BSTs let you ask "what's the next key after this one?" , dictionaries don't. You get exact matches only. The tradeoff is speed: BSTs give O(log n), we're going for O(1).
First Attempt: The Direct Access Table
The dumbest-possible approach. And it's actually a useful starting point.
Store items in a giant array, indexed directly by their key.
Want to store something with key 4? Just put it at array[4].
Want to find it later? Just look at array[4]. Done.
Insert, delete, search , all O(1). Beautiful.
So why don't we just do this?
Two reasons:
Badness #1 , Keys might not be integers. What if your key is a string? A custom object? You can't index an array with a name.
Badness #2 , Gigantic memory hog. If your keys are 64-bit integers, you'd need 2⁶⁴ slots just to store one dictionary. That's astronomically wasteful. Most slots will be null forever. Because at any moment, someone might insert a key with value 5,000,000,000. You need that slot to exist already.
So we need to fix both problems. One at a time.
Fix #1: Prehashing (Getting to Integers)
The first fix is conceptually simple: map any key to a non-negative integer.
This is called prehashing. Python calls it hash(), which is a bit confusing,
but don't let that fool you , it's just a translation step, not the real hashing yet.
In theory? Everything on a computer is already bits, and bits are integers. Done.
In practice (Python):
hash("hello") # → some integer
hash(42) # → 42 (integers map to themselves)
hash(myObject) # → uses memory address by default
One important rule: the prehash value must never change.
If you store a key, hash it, store it at position 4, and then later the hash returns 7 , you'll never find your item again. This is why Python won't let you use mutable objects (like lists) as dictionary keys. They could change.
Ideally hash(x) == hash(y) if and only if x = y.
After prehashing: every key becomes some integer.
still not solved: those integers can be huge.
Fix #2: Hashing (Shrinking the Universe)
Here's the core idea. Instead of one giant array, use a small table of size m.
Apply a hash function h(k) that maps any key to a slot in [0, m-1].
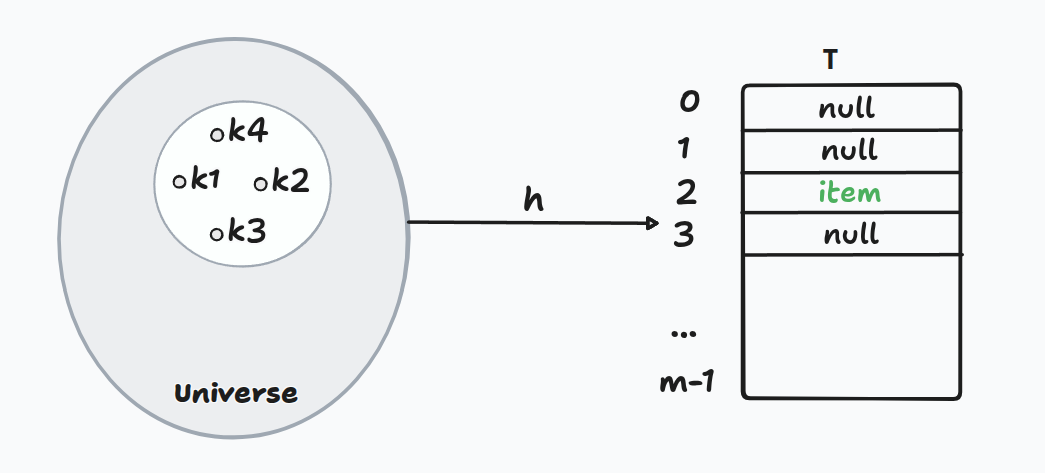
Goal: keep m roughly proportional to n (the number of items actually stored).
That way, space is O(n). Linear. Optimal.
But here's the unavoidable problem...
Collisions Are Inevitable
If you have a huge universe of possible keys crammed into m slots ,
pigeonhole principle guarantees two different keys will land in the same slot.
h(k₁) == h(k₂) but k₁ ≠ k₂
That's a collision. And no matter how clever your hash function is, you can't eliminate them entirely. So instead , you have to handle them.
Chaining: The Simple Fix
The idea is almost embarrassingly simple:
If multiple items land in the same slot, just keep them in a linked list there.
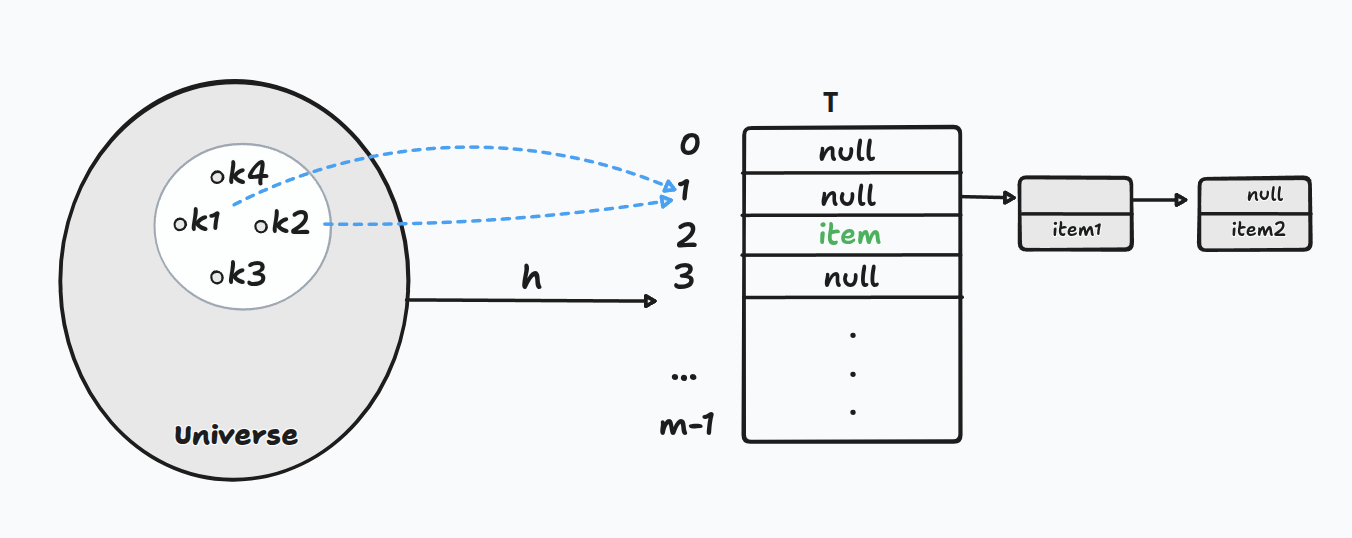
Each slot in the table holds a pointer to a chain (linked list) of items that all hashed to that position.
- Insert: hash the key, append to the list at that slot.
- Delete: hash the key, walk the list, remove it.
- Search: hash the key, walk the list, find it (or not).
This is hashing with chaining.
Why Should This Be Fast?
Worst case? All keys hash to the same slot. One giant linked list. Search becomes . Not helpful.
But worst case is not the whole story. Let's think about the expected case.
We make an assumption called Simple Uniform Hashing:
Each key is equally likely to land in any of the slots, independently of every other key.
Under this assumption, think about one specific slot. What's the chance any single key lands there? .
You have keys total. Each one lands in that slot with probability , independently. So the expected number of keys in that slot is:
That's just times . We call this the load factor:
As long as we keep — table size scales with data — stays constant. Maybe 1, maybe 2, maybe 0.7. Doesn't matter. It's a constant.
So when you search: you compute the hash in , then walk a chain of expected length . Total expected cost:
The is a floor — you always pay at least that just to compute the hash and follow the first pointer, even if the chain is empty. Then on top. Both constant → constant time.
The Cost Table
| Operation | Expected Time |
|---|---|
| Insert | O(1) |
| Delete | O(1) |
| Search | O(1) |
All O(1) , as long as the load factor stays constant.
Building a Good Hash Function
The remaining question: how do we actually build h?
There are three approaches worth knowing.
Method 1 , Division
h(k) = k mod m
Dead simple. Take the key, take the remainder when dividing by m.
Works okay in practice , if you pick m to be a prime not close
to a power of 2 or 10. Otherwise, common key patterns exploit the common factors
and cluster into only a fraction of your slots.
Not theoretically sound. Convenient but fragile.
Method 2 , Multiplication
h(k) = ((a · k) mod 2^w) >> (w - r)
Where:
w= word size of your machine (e.g. 64 bits)m = 2^r(table size is a power of 2)a= an odd integer, not close to a power of 2
The idea: multiply k by a and extract the middle r bits of the result.
Why the middle? Because those bits got contributions from many parts of k
during multiplication , carries, shifts, overlaps. They're mixed up.
The far-right bits are too predictable. The middle is where the chaos lives.
This is why hashing is called hashing , you're cutting the key into pieces and mixing them together, like chopping and tossing ingredients.
Better in practice. Still not provably good for all inputs.
Method 3 , Universal Hashing
h(k) = ((a·k + b) mod p) mod m
Where:
p= a prime larger than the universe of keysa,b= randomly chosen integers in[0, p-1]m= table size
This is the one with a real guarantee:
For any two distinct keys
k₁ ≠ k₂, no matter how adversarially chosen, the probability of a collision is at most1/m, over the random choice ofaandb.
Key distinction from the others: the randomness is in the hash function itself, not in any assumption about the input. Worst-case keys, random hash function.
This is why hashing actually works in theory , not the simple uniform hashing
assumption, but universal hashing. The expected chain length stays at α
even in the worst case (with expectation over your random choice of a and b).
Theoretically sound. This is the real deal.
The Elephant in the Room
Hash tables can't do everything.
The thing binary search trees had that hash tables don't: nearest-neighbor queries.
- "Find the next key after this one?" → BST: O(log n). Hash table: 🤷
- "Find all keys in range [lo, hi]?" → BST: O(log n + output). Hash table: 🤷
Hash tables are exact search machines. Lightning-fast if you know exactly what you're looking for. Blind if you don't.
Choose your data structure based on your query.
Summary
| What we want | Solution |
|---|---|
| Keys aren't integers | Prehashing |
| Table is too big | Hash function (shrink universe) |
| Two keys → same slot | Chaining (linked list per slot) |
| Fast expected operations | Load factor α = n/m kept constant |
| Real theoretical guarantee | Universal hashing |
The magic of hashing: an impossibly large universe of keys, crammed into a small table, with collisions handled gracefully, and (almost always) O(1) per operation.
REF
Based on MIT 6.006 lecture on Hashing with Chaining.